[ Theorie ] [ Terra-Datenbank ] [ Praxis ] [ Aufgaben ] [ Quellen ]
Kurze Einführung in die Theorie der Datenbanken
Um das Abfragen von Datenbanken genauer zu verstehen, werden wir uns zuerst den Aufbau an einem Beispiel genauer ansehen. Doch bevor wir das tun, müssen wir ein paar wichtige Begriffe kennen. Eine Datenbank besteht aus
- Daten -
- den integrierten Datensätzen und
- Software -
- dem Datenbank Management System (database management system (DBMS))
Von der Realwelt zum Modell
Stellen wir uns vor, wir wollten eine Übersicht über die Kennzahlen von Städten, Ländern, Bergen, Seen und Meeren unserer Welt anfertigen. Um die Daten bereitzustellen, würden wir einen Atlas nehmen und dort alle für uns notwendigen Angaben finden. Um die Informationen anschaulich darzustellen, gibt es zwei Möglichkeiten:
-
Wir kennen bereits eine konkrete Fragestellung, wie z. B. „Welche Städte haben mehr als 800 000 Einwohner und liegen an einem See?“. In diesem Fall können wir unsere Suche einschränken und eine entsprechende Tabelle erstellen.
-
Wir wissen nicht genau was gefragt sein wird. Wir möchten unsere Daten allerdings so aufbereiten, dass alle möglichen Fragen in kurzer Zeit beantwortet werden können. In diesem Fall sollten wir uns wohl am Atlas ein Beispiel nehmen und die Daten unter verschiedenen Stichworten in einzelne Tabellen einordnen. Alle Angaben von Städten kommen in die Tabelle „Stadt“, alle Daten zu Ländern in die Tabelle „Land“ usw.
Dieses Vorgehen führt uns zum Begriff der relationalen Datenbank, denn zwischen den von uns angefertigten Tabellen bestehen Beziehungen (Relationen), wie zum Beispiel jede Stadt liegt in einem bestimmten Land und umgekehrt liegen verschiedene Städte in einem Land.
Anders als mit den Daten im Atlas können wir unter neuer Fragestellung unsere Tabellen durch Nutzen entsprechender Relationen schnell neu zusammenstellen. Weitere Vorteile sind im Folgenden aufgeführt.
Merkmale eines Datenbankbetriebssystems
- Redundanzarme Speicherung (Integration)
- Trennung der Datenbeschreibung von den Anwendungsdaten (Katalog)
- Mehrnutzerzugriff
- Nutzerfreundlichkeit
- Gewährleistung der Datensicherheit
- Gewährleistung der physischen Datenintegrität
- Gewährleistung der operationalen Datenintegrität
- Gewährleistung der semantischen Datenintegrität
- Gewährleistung der Datensicherung
- akzeptables Antwort-Zeit-Verhalten
Die wichtigsten heute üblichen Datenbankmodelle sind:
- das hierarchische Datenbankmodell
- das Netzwerk-Modell
- das relationale Datenbankmodell
- mit Erklärungen zu den Datenbankmodellen
Um auf eine Vielzahl von Fragen antworten zu können, bietet sich also die Nutzung eines relationalen Datenbankmodells an. Es soll ein möglichst exaktes Abbild der realen Welt sein. Eine solche Miniwelt besteht aus gewissen Objekten (sogenannten Entities) wie Stadt, Land, Kontinent usw. Zwischen diesen Objekten existieren Beziehungen, die bestimmte Abläufe oder Abhängigkeiten in der Miniwelt darstellen (z. B. welche Stadt in welchem Land liegt.) Um zu einem Datenmodell zu kommen, fasst man gleichartige Objekte und gleichartige Beziehungen (sogenannten Relationships) jeweils zu Klassen zusammen. Somit ergeben sich
-
Objekttypen wie Stadt, Land, Kontinent und
-
|
K_NAME
|
FLAECHE
|
|
Afrika
|
48,00
|
|
Amerika
|
39,34
|
|
Asien
|
30,00
|
|
Australien
|
13,20
|
|
Europa
|
10,50
|
Tabelle 2: Kontinent
|
K_NAME
|
L_ID
|
PROZENT
|
|
Europa
|
A
|
100
|
|
Asien
|
ADN
|
100
|
|
Asien
|
AFG
|
100
|
|
Europa
|
AL
|
100
|
|
Europa
|
AND
|
100
|
|
Amerika
|
AUB
|
100
|
|
Australien
|
AUS
|
100
|
Tabelle 1: Ausschnitt aus Umfasst
Beziehungstypen wie Umfasst, Liegt_an.
|
EINWOHNER
|
FLAECHE
|
HAUPTSTADT
|
L_NAME
|
L_ID
|
LT_ID
|
|
7862000
|
83845
|
Wien
|
Oesterreich
|
A
|
WIE
|
|
2360000
|
332968
|
Aden
|
Jemen
|
ADN
|
ADN
|
|
18630000
|
647497
|
Kabul
|
Afghanistan
|
AFG
|
AFG
|
|
3389000
|
28748
|
Tirana
|
Albanien
|
AL
|
AL
|
|
61000
|
468
|
Andorra_la_Vella
|
Andorra
|
AND
|
AND
|
|
81500
|
442
|
Saint_Johns
|
Antigua_und_Barbuda
|
AUB
|
AUB
|
|
16028400
|
7686420
|
Canberra
|
Australien
|
AUS
|
ACT
|
Tabelle 3: Auszug aus Land
Im Gegensatz zu den nicht-relationalen Datenbank-Management-Systemen ist eine der Anforderungen an ein relationales Datenbank-Management-System (RDBMS), dass es die Daten in einfachen Tabellen abspeichert.
Relationale Datenbanksysteme
Eines der ersten Datenbanksysteme kam 1968 auf den Markt. Es war das hierarchische Datenbanksystem IMS von IBM. Sehr bald stellte man jedoch fest, dass die Möglichkeiten, die reale Welt in diesem DBMS abzubilden, nicht ausreichten.
Datenbank vs. Dateisystem
In den Anfängen der elektronischen Datenverarbeitung kannte man noch keine Datenbanksysteme. Jedes Programm speicherte seine Daten in einfachen Dateien. Diese Dateien wurden den Programmen fest zugeordnet; somit waren die gleichen Daten in der Regel mehrmals gespeichert (redundant). Falls ein Programm die Daten eines anderen Programms zur Weiterverarbeitung benötigte, wurden diese Daten in der Regel für diese spezielle Anwendung kopiert. Damals wurden die einzelnen Programme noch sequentiell nacheinander abgearbeitet. D.h. erst, wenn das eine Programm komplett abgearbeitet war, wurde das nächste Programm gestartet. Doch im Laufe der Weiterentwicklung der Datenverarbeitungsanlagen wurden die Anforderungen an die Applikationen immer anspruchsvoller. Man erwartete von den Daten einen immer aktuelleren Stand. Somit musst z.B. der Lagerbestand eines Unternehmens sofort aktualisiert werden, wenn ein Auftrag ausgeführt wurde. Es konnte ja vorkommen, dass ein anderes Programm schon kurze Zeit später’ den Lagerbestand wissen wollte, um einem Kunden Auskunft über die Liefermöglichkeiten eines Teils zu geben. Außerdem sollten diese Informationen direkt (online) vom Rechner abrufbar sein. Gleichzeitig wurde die Datenstruktur immer komplexer. Große Unternehmen hatten plötzlich Tausende von Dateien zu verwalten. Es wurden ganze Aktenschränke mit Dateibeschreibungen manuell verwaltet, die sich nie auf dem aktuellen Stand befanden. Dies war die Zeit, in der man über »zentralisierte Datenverwaltungsprogramme« nachdachte. Das waren Programme, die sowohl die Struktur (Satzaufbau) der Dateien als auch die dazugehörigen physischen Speichermedien und die Programme, die mit diesen Daten operierten, verwalteten. Somit waren die ersten Ansätze eines Datenbanksystems entstanden. Im Laufe der Zeit wurde die Funktionalität dieser Datenverwaltungsprogramme immer weiter ausgebaut. Heute haben Datenbanksysteme nicht nur das »Wissen« über Zusammenhänge der Daten untereinander, sondern sie übernehmen auch Tätigkeiten wie Überwachung vor unberechtigtem Zugriff, Datensicherung, Kontrolle des gleichzeitigen Zugriffs mehrerer Programme usw.Die Vorteile von Datenbanksystemen gegenüber herkömmlichen Dateisystemen sind vor allem in der einfacheren Programmierung zu sehen. Als die Programme noch dateiorientiert arbeiteten, musste in jedem einzelnen Programm die Datenstruktur aller benutzten Dateien definiert werden, die Programmlogik nicht nur vorwärts, sondern für den Fall des Programmabbruchs auch noch einmal rückwärts programmiert werden und falls das Programm beabsichtigte, die Daten zu ändern, musste sichergestellt sein, dass die Daten für andere Programme gesperrt waren. Da beim Einsatz eines Datenbanksystems alle diese Programmteile an einer zentralen Stelle zur Verfügung gestellt werden, ergibt sich eine immense Vereinfachung der Anwendungsprogramme. Somit werden Programmfehler vermieden. Ein weiterer Vorteil eines Datenbanksystems ist, dass die Datenbeschreibungen (Datentyp und Zusammenhänge der Daten) an zentraler Stelle in einem sogenannten Data Dictionary verwaltet werden. Dadurch werden die Anwendungsprogramme unabhängiger von Änderungen der Datenstruktur.
Grundbegriffe des relationalen Datenmodells
Das relationale Modell besteht aus der Definition von Objekten, Operationen und Regeln.
Relationale Objekte
- Domain
- Wertebereich - eine Menge möglicher Werte, die ein Attribut annehmen kann, z.B. INTEGER, MONEY oder CHAR(32).
- Attribut
- Spalte - eine bezeichnete Eigenschaft. Attribute basieren immer auf einem Wertebereich.
- Relation
- Tabelle - Menge von (gleichartigen) Tupeln mit folgenden Eigenschaften
- keine doppelten Tupel in einer Relation
- die Reihenfolge, mit der die Tupel gespeichert sind, ist nicht definiert
- die Reihenfolge, mit der die Attribute gespeichert sind, ist nicht definiert
- die Attributwerte sind atomar (keine Mengen)
- Degree
- Ausdehnungsgrad der Tabelle
- Tupel
- Datensatz - ein Tupel umfasst mehrere Attribute mit je einem zugehörigen Wertebereich. Ein Tupel fasst die interessierenden Eigenschaften eines Objektes, einer Person oder einer Beziehung zusammen.
- Beziehung (relationship)
- Beziehung zwischen Tupeln, wie zum Beispiel: eine Student besucht mehrere Vorlesungen. Beziehungen werden selbst wieder als Tupel dargestellt.
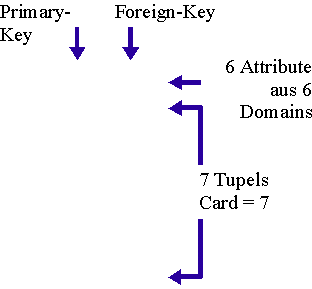
- Primary-Key
- eindeutiger Schlüssel
- Foreign-Key
- Fremdschlüssel – repräsentieren Beziehungen zwischen Tabellen
Relation, Degree, Attribut-Tupel
|
EINWOHNER
|
FLAECHE
|
HAUPTSTADT
|
L_NAME
|
L_ID
|
LT_ID
|
|
7862000
|
83845
|
Wien
|
Oesterreich
|
A
|
WIE
|
|
2360000
|
332968
|
Aden
|
Jemen
|
ADN
|
ADN
|
|
18630000
|
647497
|
Kabul
|
Afghanistan
|
AFG
|
AFG
|
|
3389000
|
28748
|
Tirana
|
Albanien
|
AL
|
AL
|
|
61000
|
468
|
Andorra_la_Vella
|
Andorra
|
AND
|
AND
|
|
81500
|
442
|
Saint_Johns
|
Antigua_und_Barbuda
|
AUB
|
AUB
|
|
16028400
|
7686420
|
Canberra
|
Australien
|
AUS
|
ACT
|
Abbildung 1: Auszug aus Land
Alle Daten einer Datenbank werden in sogenannten Relationen gespeichert. Als Relation (Tabelle) bezeichnet man eine logisch zusammenhängende Einheit von Informationen. Sie besteht aus einer festen Anzahl von Attributen (Spalten) und einer variablen Anzahl Tupel (Zeilen). Die Anzahl der Attribute einer Relation wird als Degree (Ausdehnungsgrad) bezeichnet. Eine Relation mit nur einem Attribut wird unär, eine mit zwei Attributen binär genannt. Die Relation Land hat den Degree 6. Eine Relation mit n Attributen wird n-ary genannt.Mit Kardinalität bezeichnet man die Anzahl der Tupel in einer Relation. Diese ist zeitabhängig und kann auch gleich Null sein, wenn die Relation leer ist. Eine Relation hat zusätzlich folgende Eigenschaften:
- Keine doppelten Tupel
D.h. es gibt zu keinem Zeitpunkt zwei Tupel, deren Attributwerte den gleichen Inhalt haben.
- Tupelreihenfolge
Die Reihenfolge, mit der die Tupel in einer Relation gespeichert sind, ist nicht definiert. Man darf sich also nie auf eine bestimmte Reihenfolge der Tupel in einer Relation verlassen!
- Attributreihenfolge
Die Reihenfolge der Attribute in einer Relation ist nicht definiert. Es ist also nicht möglich, das n-te Attribut einer Relation anzusprechen. Man kann ein bestimmtes Attribut nur mit seinem Namen ansprechen.
- Attributwerte sind atomar
Die Werte eines Attributes unterliegen einer Domäne. Da alle Elemente einer Domäne atomar sind, sind auch die Elemente eines Attributes atomar. Wenn eine Relation diese Eigenschaft hat, erfüllt sie die Bedingung der ersten Normalform (siehe Normalformen).
Primary-Key, Foreign-Key
Jede Relation besitzt genau einen Primary-Key (Primärschlüssel), um ein Tupel der Relation eindeutig zu identifizieren. Er wird definiert, indem eine der eindeutigen (unique) Attributmengen zum »Primary-Key« erklärt oder ein neues Attribut speziell für diesen Zweck eingeführt wird (z.B. eine Nummer). Ein solcher Primary-Key darf keine Null-Werte enthalten. ... Der Primary-Key soll mindestens einen Zugriffspfad garantieren, mit dem exakt ein Tupel angesprochen werden kann. Mit Hilfe dieses Primary-Keys werden meist die Verknüpfungen (Joins) der Relationen in der Datenbank hergestellt.
Betrachten wir noch einmal die Tabellen 1, 2 und 3 von Seite . Wir können die Namen aller Länder, die nicht nur auf einem Kontinent liegen, heraussuchen, indem wir die Tabelle Land mit der Tabelle Umfasst verbinden. Dazu nutzen wir den Primärschlüssel L_ID aus Land und den Fremdschlüssel L_ID aus Umfasst. Der SQL-Befehl für die Abfrage der beiden Tabellen lautet:
SELECT L_NAME
FROM UMFASST, LAND
WHERE UMFASST.L_ID = LAND.L_ID AND UMFASST.PROZENT < 100.
In der Relation Umfasst wurde ein Foreign-Key definiert: L_ID. Er wird Foreign-Key genannt, da seine Wertemenge (Domäne) in einer anderen Relation als Primary-Key definiert ist. Beide Attribute (oder Attributmengen, wenn der Key aus mehr als einem Attribut besteht) müssen zu den gleichen Domäne gehören.Es ist wichtig, dass ein Datenbanksystem weiß, welche Attributmenge den Primary-Key definiert und welche Foreign-Keys existieren. Nur so kann das DBMS die referenzielle Integrität der Datenbank gewährleisten.Aus Performancegründen können zusätzlich beliebig viele Keys in einer Relation definiert werden. Diese werden dann Alternate-Keys oder auch Secondary-Keys (Zweitschlüssel) genannt.
Relationale Operationen
- Restriction
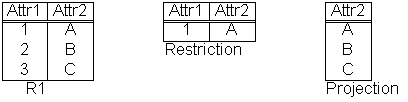
Abbildung 2
- Zeilenselektion (siehe Abb. 2)
- Projection
- Spaltenselektion (siehe Abb. 2)
- Product
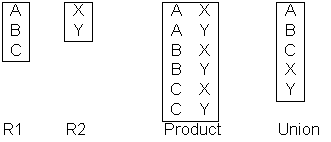
Abbildung 3
- kartesisches Produkt – jede Zeile der einen Tabelle wird mit jeder Zeile der anderen Tabelle verknüpft (siehe Abb. 3)
- Union
- Vereinigung (siehe Abb. 3)
- Intersection

Abbildung 4
- Schnittmenge (siehe Abb. 4)
- Difference
- Differenz (siehe Abb. 4)
- Join
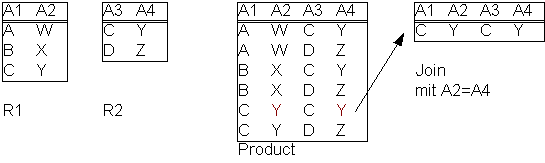
Abbildung 5
- Verbindung (siehe Abb. 5)